
 矚目客戶端
矚目客戶端 矚目小T
矚目小T 矚目大板
矚目大板 矚目會議室系統
矚目會議室系統 矚目直播
矚目直播
 多媒體通信平臺
多媒體通信平臺 多媒體通信終端
多媒體通信終端 多媒體通信軟件
多媒體通信軟件 網絡音頻處理器
網絡音頻處理器
 變電站智能巡檢機器人
變電站智能巡檢機器人 發電廠智能巡檢機器人
發電廠智能巡檢機器人 配電室智能巡檢機器人
配電室智能巡檢機器人 室內工業智能巡檢機器人
室內工業智能巡檢機器人 機器人遠程專家診斷協同平臺解決方案
機器人遠程專家診斷協同平臺解決方案





吳恩達說人工智能永恒的春天已經到來,你準備好了嗎?
時間:2017-04-01
(轉載自36氪,如有侵權請聯系刪除)

2017年2月,百度首席科學家、Coursera的聯合創始人Andrew Ng在斯坦福MSx未來論壇上的一個演講,吸引了全球的眼球。 他認為,人工智能(AI)對未來許多行業帶來的變革,如同100多年前,美國“觸電”一樣——電對制造、運輸、農業(尤其是冷藏)、醫療等等帶來了劃時代的變革。
AI驅動著百度的搜索和廣告,調度百度外賣的快遞員,選擇路線,和預估運送時間。AI正在徹底改變金融工程,對物流的轉變進行了一半,醫療和自動駕駛剛開始,而前景巨大。和“電”帶來的變革一樣,很難想象哪個行業不會被AI改變。
監督學習
驅動百億的市場容量的,基本上屬于同一種AI: 監督學習(Supervised learning),即用AI來確定A-->B的映射——輸入A和響應B的映射。
用Email作為輸入A,判斷是否是垃圾郵件是響應B。
用圖像作為輸入,識別這是一千種物體中的哪種?
從聲音A到文字B,從英文到法文,或從文字到聲音。
軟件可以學習這些輸入A到響應B的映射——有很多好的工具來讓機器學習。比如50,000小時的音頻和對應的文本,就能讓機器學到如何從音頻內容轉化為文本內容。通過大量的電郵數據和區分垃圾的標簽,也可以很快地訓練出一個垃圾郵件過濾器。
現在的AI還很初級——A到B的映射而已,不過已經推動著很大的市場。百度有很好的算法來預測某用戶是否會點擊某廣告。向受眾呈現更相關的廣告,能為互聯網營銷和廣告公司帶來極大的賺錢機會。這可能是AI最賺錢的應用。
在哪些產品里能用到AI?
產品經理常常希望了解AI能實現的,和不能實現的。一個簡單的思路是:一般人能在一秒內想出來的事情,現在或很快就可以用AI自動實現。
AI進展最快的領域正是人能做得到的領域。比如自動駕駛。人類能駕駛,所以AI也能駕駛。在醫學影像閱片和分析上,人類放射科醫生能夠閱片,所以AI也很可能在未來幾年內做到。
而人類難以做到的事情,比如預測股市變化,AI可能也難。
原因1:人類能做的,至少是可行的;
原因2:可以利用人類的數據作為培訓樣本,比如前面提到的輸入A和響應B;
原因3:人類能提供指導。如果AI對某個放射影像的結論有誤,設計者可以向醫生請教,醫生所做的正確結論的原因是什么? 進而對AI進行改善。
在Andrew Ng所接觸到的80-90%的AI項目中,都遵循這一規律:在人類能做到的領域,AI的進展更快。很多項目的發展一旦超越人類水準,發展也會變得緩慢。這也帶來一個社會矛盾:如果AI和人的水平類似,實質上是跟人類競爭。
AI的發展趨勢
AI已經出現了幾十年了,而近五年發展明顯加速,為什么?
當以前的機器學習算法性能上升到一定程度,即使再增加數據樣本量(前文談到的輸入A、響應B的A-B映射),性能改善也很有限。似乎超過一定樣本量之后,再多的數據也對算法不起作用。
而過去幾年,主要由于GPU,我們終于實現了能利用這么巨大的數據集的機器學習軟件。將數據輸入一個小的神經網絡,當超過一定性能后,上升變得平緩。而不斷地把數據輸入一個很大的神經網絡時,即使性能上升沒有那么快,也會保持上升趨勢,隨著數據量的增大,不斷提高。
因此,要想獲得很好的AI性能,需要兩樣東西:
很大的A-B映射的數據集;
大的神經網絡。現在常用的大型神經網絡建立在HPC高性能計算集群上。
現在的大型AI團隊包括機器學習和高性能計算兩組人,才能獲得足夠計算能力。百度AI團隊里的這兩種人員都專注于各自領域,沒有人能兩者兼備。
什么是神經網絡?有沒可能取代人類大腦?
問題是,我們不清楚人腦如何工作,所以很難造出取代人類大腦的神經網絡。
什么是神經網絡?先看個最簡單的神經網絡:
如果想輸入房屋面積,得到房屋總價,可以用面積-總價的一階近似的線性模型來描述這個神經網絡。
或者用更多因素建模,比如通過面積和臥室數,從第一個神經元得到可以支持的家庭人數。再通過所在地址的郵編和社區富裕程度,從第二個神經元得到附近學校的質量。
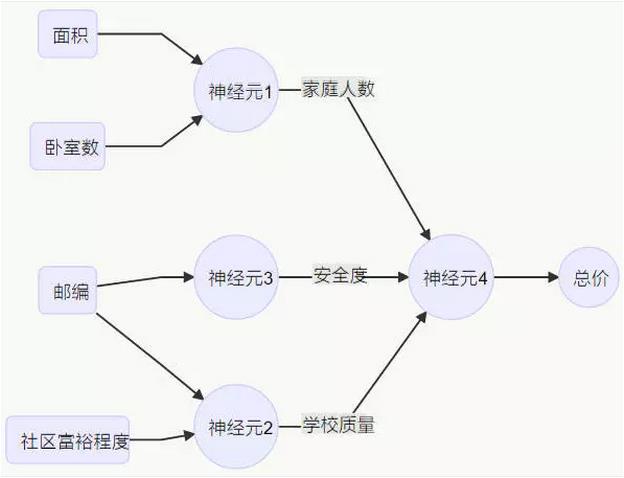
這就成為一個神經網絡。面積、臥室數、郵編、社區富裕程度屬于“輸入”集合A,總價屬于“響應”集合B。
好處在于,當訓練這樣一個神經網絡時,用戶無需關心中間因素,諸如家庭人數、安全度、學校質量等,也無需關心每個神經元如何將輸入映射到中間結果。只需要給出輸入集合A和響應集合B,神經網絡將自動形成中間的計算過程和參數。當A和B的集合足夠大,神經網絡可以自動算出很多東西。 神經網絡看上去非常簡單,讓很多初學者覺得有點失望,但它確實能解決很多問題。關鍵在于數據量要夠大——幾萬或幾十萬個樣本本身能提供大量的信息,而軟件本身只是一小部分。
如何保護AI業務?
AI研究較前沿的團隊都比較開放,常常發布研究成果。百度的AI研究論文也沒有隱藏什么成果——在人臉識別等論文里,都分享了所有的細節。既然很難把算法本身隱藏起來,如何保護AI業務? 當前稀缺資源有兩種,一種是數據,二是人才。獲取巨量數據很難,要包括輸入A+響應B。比如語音識別用了5萬小時的音頻來訓練,今年準備用10萬小時,相當于百度10年積累的音頻。
以人臉識別所用的訓練圖像數量為例
學術上最常用的基準測試/比賽:1百萬幅;
所用圖像數最多的計算機視覺對象識別學術論文:1500萬幅;
百度用來訓練世界上最先進的人臉識別系統:兩億幅!
如果只是5-10人的研發團隊,很難獲得這樣規模的數據。百度這樣的大企業的經常推出一些新產品不一定是為了營收,而是為了數據,然后通過后續的產品來獲得收益。
另一個稀缺資源是人才。AI的應用需要根據具體業務場景來定制。僅僅下載個開源包,無法解決問題。實際情況下,是否適合用某種垃圾郵件識別或語音識別技術?針對某種場景,機器學習怎么用? 所以各個公司都在為數據挖掘爭奪AI人才,來定制AI技術,找到所需要的A和B各自代表什么,怎么找到這些數據和如何調整算法來適應業務場景。
AI的良性循環
先做出某種產品。比如通過語音識別,以語音實現搜索;
然后吸引來很多用戶,用戶產生數據;
再通過機器學習,用數據改善產品。
這就形成了AI產品的良性循環。最好的產品能獲得最多的用戶,帶來最多的數據,通過現代機器學習體系,能得到最好的AI,最終讓產品變得更好,周而復始。
百度發布新的產品,會特別考慮怎樣推動這樣的良性循環,會包括相當先進的產品發布策略,比如按地理區域、細分市場等,來更好地推動這個循環。
這種良性循環的理念很早就有了,只是最近變得更加明顯。正如前文所述,當數據超過一定規模后,傳統AI算法無法明顯改善AI性能,因此數據多的優勢不明顯,大公司也很難保護自己的AI業務。現在數據越多,AI性能越好,大公司也更容易保護自己的優勢。
AI炒作的非良性循環
許多人擔心AI會不會取代或威脅人類。有一小部分研究AI的人專門從事對“邪惡AI”的炒作,以獲得投資人或政府機構的投資,來研究“反邪惡AI”。道高一尺,魔高一丈,又進一步推動對“邪惡AI”的炒作,從而形成非良性循環,非常不健康。
擔心AI變得邪惡,類似于擔心火星的未來人口過剩。現在看不出AI將會怎樣走偏,因此也談不上有針對地研究相應措施。 研究本身沒有問題,不同的研究是好事,但是對邪惡AI的研究占用不恰當的資源,就不應該了。兩個人,或者10個人來研究邪惡AI也許沒問題,但是現在投資得太多。
AI對就業的影響
AI對就業帶來的影響更讓人擔心。有些AI項目確實是瞄準了某些人類崗位,而從事這些工作的人并不清楚嚴重性。硅谷創造了大量財富,但也應該對其造成的問題承擔責任,比如造成的失業問題。AI取代人類崗位的現實問題,更應該引起重視,而不是被邪惡AI的炒作轉移了注意力。
AI產品管理
AI是個讓人興奮的領域,同時也存在一些挑戰。 如何將AI融入公司業務?
產品經理的職責是找到用戶喜歡的,而工程師的角色是做出可行的產品。兩者共同協作,才能做出理想的產品。
AI是個新生事物,所以技術公司以前的流程和工作方法,不太適用。硅谷的產品經理和工程師的合作已有一套標準流程。比如開發APP時,產品經理先畫出線框圖,比如logo,按鈕,各個板塊等,工程師再寫出代碼來實現。但是AI的APP無法通過畫線框來描述。通過什么形式,把產品經理頭腦里對AI產品的功能要求明白地分享給工程師呢?
比如開發語音識別系統,實現語音搜索,有很多改善方向。比如:
在嘈雜環境下如何改善,比如車里或咖啡館?
僅改善窄帶語音信號;
對不同口音改善;
百度發現,產品經理通過數據和工程師溝通,是個較好的辦法。 產品經理負責提供測試數據集給工程師,比如一萬個音頻和對應的文字,來說明所關心的問題,工程師也能更明白需要解決的問題。如果這些音頻里有大量車輛噪音,工程師就知道車輛噪音是問題。 如果是混合了幾種不同噪聲,工程師也能想辦法解決。最糟糕的情況是,產品經理提供的測試數據,并不能代表自己想解決的問題,那就出問題了。
同時,新產品設計的流程有很多, 比如想設計一個交流型AI機器人:
- 人:“我想叫個外賣”;
- AI:“你喜歡哪種類型餐館?”;
- 人:“川菜”;
- AI:“這些可供選擇,xxx,yyy,zzz,...”;
線框圖只能顯示對話過程,無法描述所需AI的復雜程度等。百度的產品經理和工程師會在一起,寫五十種對話,
- 人:“請幫我定一個結婚紀念日的餐館”;
- AI:“你需要訂花嗎?”;
這時候,工程師會問一些更具體的問題,比如每種場景是否都需要繼續提配套產品的問題,比如談到圣誕節時,是否要問對方要不要買圣誕裝飾?一起思考,共同討論需求和技術,很有效。
對AI的宣傳里,有很多吸引眼球的技術,不過它們未必最有用。如何將吸引眼球的技術和產品、業務相結合?軟件產業已經有標準流程,比如代碼審查、敏捷開發等,如何組織AI的產品工作,有很長的路要走,現在正是考慮這些問題的時候。
短期內,AI有哪些機會?
語音識別正在起飛
最近準確率已經提高到很有用的程度。4-5個月之前,斯坦福大學計算機系教授James Landay、百度、華盛頓大學一起展示了在手機上輸入英文和普通話,用語音識別的速度比用手機輸入快3倍。去年百度的所有語音識別產品年度環比增長大約100%,現在正是語音識別技術騰飛之時。美國有幾個公司做智能語音控制器(Smart Speakers),用語音控制家用設備也會很快推廣。相關的操作系統和硬件都會很快發布。
計算機視覺也即將到來
中國的人臉識別發展速度很快。因為中國的手機比筆記本更普及,很多人有手機,而不一定有筆記本。 在中國可以僅僅憑手機申請助學貸款。涉及到錢,所以需要先驗證身份和很多東西。這加速了人臉識別的發展。通過手機進行人臉識別,作為 用生物標識進行身份認證的一種方法,在中國發展很快。
在百度總部,不需要RFID卡進行認證,而是直接刷臉進門,Andrew Ng在YouTube上有一段視頻。現在人們對人臉識別技術已經足夠信任,并在安全要求較高的場景下使用。
百度在語音識別和計算機識別上的資金投入和數據投入巨大,任何小開發團體遠遠無法相提并論,也不太可能有其他出乎意料的技術突破。
醫療健康的AI應用
Andrew Ng對AI對醫療健康領域帶來的影響很看好。很多現在的放射科醫生會被AI影響到。如果想在放射科一直工作四十年,不是個好的職業計劃。
還有很多垂直領域將受到AI的影響,比如金融工程和教育。不過短期之內還不太會對教育產生實質性的影響。
永恒的春天
光從監督學習已經看得出AI將如何逐漸改變各個行業。其他的AI形式,比如無監督學習、強化學習、遷移學習等等,都還在研究階段,現在的市場規模較小。
有很多行業會經歷幾個冬天,然后迎來永恒的春天。AI經歷過兩個冬天,現在已經進入永恒的春天。就像硅的春天一樣,半導體、晶體管、計算周期這些都將和人類一起發展很久。神經網絡和深度學習會繁榮很長時間,一百年或許太遠,但一些重要應用改變幾個大行業的路線圖已經很清晰。
AI確實正在取代人類的一些崗位。當某些崗位被AI取代后,我們需要新的教育系統,來幫助失去工作的人獲得新的技能。政府應該為這些愿意學習新技能的人,提供基本收入保障,重新成為勞動者的一員。我們需要新的系統和結構,來讓幫助社會向新世界進化。雖然會有新類型的工作,但工作崗位的消失也比以前更快。
一些問題
大公司在數據和人才上有巨大優勢,那么創業公司的機會在哪里? 投資者可以關注哪種規模的創新?
在語音識別、人臉識別上,小公司非常難與大公司競爭,除非有意料之外的技術突破。同時,也有很多小垂直領域適合創業公司,比如醫療影像。有一些疾病的病例不多,如果有一千張影像,也許就涵蓋了所有所需的數據了,一些垂直領域需要的數據量也不大。
另外,AI的機遇非常多,大公司會放棄很多的小的垂直市場,因為精力有限,大的機會還研究不過來。
AI在發明創造上,有哪些進展?
還很早期。AI可以作曲,但這很主觀。20年前的技術做出來的曲子有人喜歡,有人不喜歡。有些項目用AI制作圖片特效,用特效模仿某畫家作品,這些都是小而有趣的領域。 現在還看不到有什么技術路線能發明復雜的系統。
如果摩爾定律不再成立,對AI的擴展性有什么影響?
一些高性能計算公司的硬件路線圖顯示,摩爾定律在單芯片上不再那么有效,但神經網絡、深度學習所需的計算類型在未來幾年仍然能很好地擴展。SIMD(單指令多數據)讓并行化處理負載非常容易。神經網絡很容易并行化,加速計算的空間還很大。
AI面對的諸多問題中,許多問題的瓶頸在于數據,也有很多的瓶頸在于計算速度——能便宜地處理數據的速度趕不上獲得數據的速度。所以高性能計算的路線圖應該包括這方面。
算法是AI里的特殊作料。是否應通過知識產權保護,還是繞過這個問題去設計產品? 對機器學習的研究者,是否有和AI產品經理-工程師那樣類似的流程或良性循環,來實現突破或改善研究流程?
知識產權的問題比較難講。有些公司申請了大量專利,但是是否真能帶來實質性的保護?所以我們往往從如何從戰略上思考細節,比如讓數據保護自己。
研究機構更偏好新鮮、搶眼球的東西,來發表論文。訓練新研究者的辦法通常是讀很多論文。而大家常常忽視重復論文里的試驗的重要性。不一定要把精力大量用于發明新東西,而花時間重復別人的發布結果也是很好的培訓方法。和培訓博士生一樣:去學習和理解別人的論文,重復別人的試驗,爭取獲得類似的結果,很快你就能產生自己的想法去推動最新的科技。
對希望從事機器人相關工作的機械工程學生,有哪些和AI、機器人相關的機會比較適合?
很多機械工程背景的人,在AI領域很成功。可以上一些計算機/AI課程,和AI領域的老師聊聊。一些垂直領域存在有趣的AI機器人的機會,比如精準農業。Blue River用計算機視覺來區分不同植物,比如不同品種卷心菜,選擇留下哪些,除掉哪些,來提高產量。
中國也生產和銷售很多社交和伴侶機器人,美國還沒起怎么起步。
讓AI和人配合起來的前景如何?很多AI應用是基于AI自己,如果采用AI+人的混合方案?比如自動駕駛等?
沒有統一的規則,應該跟實際情況有關。很多語音識別是為了讓人類更高效,比如通過手機。對自動駕駛汽車,可能需要10-15秒來轉換控制權,因為難讓容易分神的人快速接手駕駛,很困難。這種情況下,由AI獨立控制更安全。 所以從使用者角度來講,人類和AI混合的自動化比較困難。
對在線教育而言,主要問題是動機,人們不愿意花那么多時間來學完整個課程。這是不是最大的挑戰? 其他還有什么挑戰?
AI對在線教育有幫助。個性化的輔導已經談論了很長時間,Coursera用AI推薦個性化的課程,自動打分,在細節上確實有幫助。但在利用AI之前,教育的數字化還有很長的路要走。很多行業都有個規律:先有數據,再有AI,比如醫療,美國電子病歷(EHR)的進展很大。隨著電子病歷的興起,影像膠片變成數碼圖片,這些數字化產生了很多數據供AI使用,并產生價值。教育需要先經歷數字化,這一階段還有很多工作要做。
百度如何用AI來管理自己的云上數據中心? 比如IT運維管理的例子?
兩年前,百度做了個項目,可以提前一天自動檢測出硬件故障,特別是硬盤故障。這就可以事先拷貝、熱插拔進行預防處理。還可以降低數據中心的用電量,負載均衡等,都是很多小細節的改善。
能否舉一些例子說明能通過仔細地建模和規劃,用AI解決的復雜問題?對這些問題,人類可能需要進行長時間的思考。
亞馬遜是個很好的例子。它知道我瀏覽過什么,讀過什么,比我太太更了解。電腦對人們看過什么,點擊過什么廣告更了解,所以在廣告方面做得非常好。 對于有些任務,計算機可以處理的信息量遠遠超過人類,并根據規律建模,進行預測,這方面AI比人做得更好。
將AI融入人類工作的很大一部分,是將一塊塊的AI部分串成一個大系統。比如為了造自動駕駛汽車,要用相機拍攝的圖像,雷達等,組成車前方的一幅圖,再由監督學習估算和其他車的距離,以及和行人的距離,這只是兩個重要的AI部件,還需要其他的部件來估計5秒后車的位置,行人的方向。還有一個部件來分析,根據行人車輛等不同對象的運動情況,我應該怎么走? 然后還需要算方向盤的旋轉程度,以此類推。
所以復雜的AI系統有很多小AI部件,工程人員要知道如何將這種超級學習能力融合到更大的系統里,來創造價值。
產品經理和社會學家、律師等如何協調?比如自動駕駛汽車在撞人前,開發者和AI應從駕駛者,還是行人的角度考慮問題?這只是個法律問題,但也有很多類似情況。產品管理者和不同的功能部門的合作時,應該扮演什么角色?
這個問題的一個相似版本是“有軌電車”問題,會產生倫理矛盾。一個電車走到岔道口,繼續往前會撞死5個人,你可以用扳手將電車扳到另一條軌道,撞死該軌道上的一個人,而你成為兇手,你扳嗎?
除了在哲學課里,很少有誰在現實生活里遇到過這個問題,所以,它并不重要。自動駕駛的開發者沒去討論它。實際上,如果誰真正遇到了,可能之前已經犯了其他錯誤了。自動駕駛處理的問題更實際,和你自己開車一樣。比如,對面有個白色的大車,是否能及時剎車?
2017年2月,百度首席科學家、Coursera的聯合創始人Andrew Ng在斯坦福MSx未來論壇上的一個演講,吸引了全球的眼球。 他認為,人工智能(AI)對未來許多行業帶來的變革,如同100多年前,美國“觸電”一樣——電對制造、運輸、農業(尤其是冷藏)、醫療等等帶來了劃時代的變革。
AI驅動著百度的搜索和廣告,調度百度外賣的快遞員,選擇路線,和預估運送時間。AI正在徹底改變金融工程,對物流的轉變進行了一半,醫療和自動駕駛剛開始,而前景巨大。和“電”帶來的變革一樣,很難想象哪個行業不會被AI改變。
監督學習
驅動百億的市場容量的,基本上屬于同一種AI: 監督學習(Supervised learning),即用AI來確定A-->B的映射——輸入A和響應B的映射。
用Email作為輸入A,判斷是否是垃圾郵件是響應B。
用圖像作為輸入,識別這是一千種物體中的哪種?
從聲音A到文字B,從英文到法文,或從文字到聲音。
軟件可以學習這些輸入A到響應B的映射——有很多好的工具來讓機器學習。比如50,000小時的音頻和對應的文本,就能讓機器學到如何從音頻內容轉化為文本內容。通過大量的電郵數據和區分垃圾的標簽,也可以很快地訓練出一個垃圾郵件過濾器。
現在的AI還很初級——A到B的映射而已,不過已經推動著很大的市場。百度有很好的算法來預測某用戶是否會點擊某廣告。向受眾呈現更相關的廣告,能為互聯網營銷和廣告公司帶來極大的賺錢機會。這可能是AI最賺錢的應用。
在哪些產品里能用到AI?
產品經理常常希望了解AI能實現的,和不能實現的。一個簡單的思路是:一般人能在一秒內想出來的事情,現在或很快就可以用AI自動實現。
AI進展最快的領域正是人能做得到的領域。比如自動駕駛。人類能駕駛,所以AI也能駕駛。在醫學影像閱片和分析上,人類放射科醫生能夠閱片,所以AI也很可能在未來幾年內做到。
而人類難以做到的事情,比如預測股市變化,AI可能也難。
原因1:人類能做的,至少是可行的;
原因2:可以利用人類的數據作為培訓樣本,比如前面提到的輸入A和響應B;
原因3:人類能提供指導。如果AI對某個放射影像的結論有誤,設計者可以向醫生請教,醫生所做的正確結論的原因是什么? 進而對AI進行改善。
在Andrew Ng所接觸到的80-90%的AI項目中,都遵循這一規律:在人類能做到的領域,AI的進展更快。很多項目的發展一旦超越人類水準,發展也會變得緩慢。這也帶來一個社會矛盾:如果AI和人的水平類似,實質上是跟人類競爭。
AI的發展趨勢
AI已經出現了幾十年了,而近五年發展明顯加速,為什么?
當以前的機器學習算法性能上升到一定程度,即使再增加數據樣本量(前文談到的輸入A、響應B的A-B映射),性能改善也很有限。似乎超過一定樣本量之后,再多的數據也對算法不起作用。
而過去幾年,主要由于GPU,我們終于實現了能利用這么巨大的數據集的機器學習軟件。將數據輸入一個小的神經網絡,當超過一定性能后,上升變得平緩。而不斷地把數據輸入一個很大的神經網絡時,即使性能上升沒有那么快,也會保持上升趨勢,隨著數據量的增大,不斷提高。
因此,要想獲得很好的AI性能,需要兩樣東西:
很大的A-B映射的數據集;
大的神經網絡。現在常用的大型神經網絡建立在HPC高性能計算集群上。
現在的大型AI團隊包括機器學習和高性能計算兩組人,才能獲得足夠計算能力。百度AI團隊里的這兩種人員都專注于各自領域,沒有人能兩者兼備。
什么是神經網絡?有沒可能取代人類大腦?
問題是,我們不清楚人腦如何工作,所以很難造出取代人類大腦的神經網絡。
什么是神經網絡?先看個最簡單的神經網絡:
如果想輸入房屋面積,得到房屋總價,可以用面積-總價的一階近似的線性模型來描述這個神經網絡。
或者用更多因素建模,比如通過面積和臥室數,從第一個神經元得到可以支持的家庭人數。再通過所在地址的郵編和社區富裕程度,從第二個神經元得到附近學校的質量。
這就成為一個神經網絡。面積、臥室數、郵編、社區富裕程度屬于“輸入”集合A,總價屬于“響應”集合B。
好處在于,當訓練這樣一個神經網絡時,用戶無需關心中間因素,諸如家庭人數、安全度、學校質量等,也無需關心每個神經元如何將輸入映射到中間結果。只需要給出輸入集合A和響應集合B,神經網絡將自動形成中間的計算過程和參數。當A和B的集合足夠大,神經網絡可以自動算出很多東西。 神經網絡看上去非常簡單,讓很多初學者覺得有點失望,但它確實能解決很多問題。關鍵在于數據量要夠大——幾萬或幾十萬個樣本本身能提供大量的信息,而軟件本身只是一小部分。
如何保護AI業務?
AI研究較前沿的團隊都比較開放,常常發布研究成果。百度的AI研究論文也沒有隱藏什么成果——在人臉識別等論文里,都分享了所有的細節。既然很難把算法本身隱藏起來,如何保護AI業務? 當前稀缺資源有兩種,一種是數據,二是人才。獲取巨量數據很難,要包括輸入A+響應B。比如語音識別用了5萬小時的音頻來訓練,今年準備用10萬小時,相當于百度10年積累的音頻。
以人臉識別所用的訓練圖像數量為例
學術上最常用的基準測試/比賽:1百萬幅;
所用圖像數最多的計算機視覺對象識別學術論文:1500萬幅;
百度用來訓練世界上最先進的人臉識別系統:兩億幅!
如果只是5-10人的研發團隊,很難獲得這樣規模的數據。百度這樣的大企業的經常推出一些新產品不一定是為了營收,而是為了數據,然后通過后續的產品來獲得收益。
另一個稀缺資源是人才。AI的應用需要根據具體業務場景來定制。僅僅下載個開源包,無法解決問題。實際情況下,是否適合用某種垃圾郵件識別或語音識別技術?針對某種場景,機器學習怎么用? 所以各個公司都在為數據挖掘爭奪AI人才,來定制AI技術,找到所需要的A和B各自代表什么,怎么找到這些數據和如何調整算法來適應業務場景。
AI的良性循環
先做出某種產品。比如通過語音識別,以語音實現搜索;
然后吸引來很多用戶,用戶產生數據;
再通過機器學習,用數據改善產品。
這就形成了AI產品的良性循環。最好的產品能獲得最多的用戶,帶來最多的數據,通過現代機器學習體系,能得到最好的AI,最終讓產品變得更好,周而復始。
百度發布新的產品,會特別考慮怎樣推動這樣的良性循環,會包括相當先進的產品發布策略,比如按地理區域、細分市場等,來更好地推動這個循環。
這種良性循環的理念很早就有了,只是最近變得更加明顯。正如前文所述,當數據超過一定規模后,傳統AI算法無法明顯改善AI性能,因此數據多的優勢不明顯,大公司也很難保護自己的AI業務。現在數據越多,AI性能越好,大公司也更容易保護自己的優勢。
AI炒作的非良性循環
許多人擔心AI會不會取代或威脅人類。有一小部分研究AI的人專門從事對“邪惡AI”的炒作,以獲得投資人或政府機構的投資,來研究“反邪惡AI”。道高一尺,魔高一丈,又進一步推動對“邪惡AI”的炒作,從而形成非良性循環,非常不健康。
擔心AI變得邪惡,類似于擔心火星的未來人口過剩。現在看不出AI將會怎樣走偏,因此也談不上有針對地研究相應措施。 研究本身沒有問題,不同的研究是好事,但是對邪惡AI的研究占用不恰當的資源,就不應該了。兩個人,或者10個人來研究邪惡AI也許沒問題,但是現在投資得太多。
AI對就業的影響
AI對就業帶來的影響更讓人擔心。有些AI項目確實是瞄準了某些人類崗位,而從事這些工作的人并不清楚嚴重性。硅谷創造了大量財富,但也應該對其造成的問題承擔責任,比如造成的失業問題。AI取代人類崗位的現實問題,更應該引起重視,而不是被邪惡AI的炒作轉移了注意力。
AI產品管理
AI是個讓人興奮的領域,同時也存在一些挑戰。 如何將AI融入公司業務?
產品經理的職責是找到用戶喜歡的,而工程師的角色是做出可行的產品。兩者共同協作,才能做出理想的產品。
AI是個新生事物,所以技術公司以前的流程和工作方法,不太適用。硅谷的產品經理和工程師的合作已有一套標準流程。比如開發APP時,產品經理先畫出線框圖,比如logo,按鈕,各個板塊等,工程師再寫出代碼來實現。但是AI的APP無法通過畫線框來描述。通過什么形式,把產品經理頭腦里對AI產品的功能要求明白地分享給工程師呢?
比如開發語音識別系統,實現語音搜索,有很多改善方向。比如:
在嘈雜環境下如何改善,比如車里或咖啡館?
僅改善窄帶語音信號;
對不同口音改善;
百度發現,產品經理通過數據和工程師溝通,是個較好的辦法。 產品經理負責提供測試數據集給工程師,比如一萬個音頻和對應的文字,來說明所關心的問題,工程師也能更明白需要解決的問題。如果這些音頻里有大量車輛噪音,工程師就知道車輛噪音是問題。 如果是混合了幾種不同噪聲,工程師也能想辦法解決。最糟糕的情況是,產品經理提供的測試數據,并不能代表自己想解決的問題,那就出問題了。
同時,新產品設計的流程有很多, 比如想設計一個交流型AI機器人:
- 人:“我想叫個外賣”;
- AI:“你喜歡哪種類型餐館?”;
- 人:“川菜”;
- AI:“這些可供選擇,xxx,yyy,zzz,...”;
線框圖只能顯示對話過程,無法描述所需AI的復雜程度等。百度的產品經理和工程師會在一起,寫五十種對話,
- 人:“請幫我定一個結婚紀念日的餐館”;
- AI:“你需要訂花嗎?”;
這時候,工程師會問一些更具體的問題,比如每種場景是否都需要繼續提配套產品的問題,比如談到圣誕節時,是否要問對方要不要買圣誕裝飾?一起思考,共同討論需求和技術,很有效。
對AI的宣傳里,有很多吸引眼球的技術,不過它們未必最有用。如何將吸引眼球的技術和產品、業務相結合?軟件產業已經有標準流程,比如代碼審查、敏捷開發等,如何組織AI的產品工作,有很長的路要走,現在正是考慮這些問題的時候。
短期內,AI有哪些機會?
語音識別正在起飛
最近準確率已經提高到很有用的程度。4-5個月之前,斯坦福大學計算機系教授James Landay、百度、華盛頓大學一起展示了在手機上輸入英文和普通話,用語音識別的速度比用手機輸入快3倍。去年百度的所有語音識別產品年度環比增長大約100%,現在正是語音識別技術騰飛之時。美國有幾個公司做智能語音控制器(Smart Speakers),用語音控制家用設備也會很快推廣。相關的操作系統和硬件都會很快發布。
計算機視覺也即將到來
中國的人臉識別發展速度很快。因為中國的手機比筆記本更普及,很多人有手機,而不一定有筆記本。 在中國可以僅僅憑手機申請助學貸款。涉及到錢,所以需要先驗證身份和很多東西。這加速了人臉識別的發展。通過手機進行人臉識別,作為 用生物標識進行身份認證的一種方法,在中國發展很快。
在百度總部,不需要RFID卡進行認證,而是直接刷臉進門,Andrew Ng在YouTube上有一段視頻。現在人們對人臉識別技術已經足夠信任,并在安全要求較高的場景下使用。
百度在語音識別和計算機識別上的資金投入和數據投入巨大,任何小開發團體遠遠無法相提并論,也不太可能有其他出乎意料的技術突破。
醫療健康的AI應用
Andrew Ng對AI對醫療健康領域帶來的影響很看好。很多現在的放射科醫生會被AI影響到。如果想在放射科一直工作四十年,不是個好的職業計劃。
還有很多垂直領域將受到AI的影響,比如金融工程和教育。不過短期之內還不太會對教育產生實質性的影響。
永恒的春天
光從監督學習已經看得出AI將如何逐漸改變各個行業。其他的AI形式,比如無監督學習、強化學習、遷移學習等等,都還在研究階段,現在的市場規模較小。
有很多行業會經歷幾個冬天,然后迎來永恒的春天。AI經歷過兩個冬天,現在已經進入永恒的春天。就像硅的春天一樣,半導體、晶體管、計算周期這些都將和人類一起發展很久。神經網絡和深度學習會繁榮很長時間,一百年或許太遠,但一些重要應用改變幾個大行業的路線圖已經很清晰。
AI確實正在取代人類的一些崗位。當某些崗位被AI取代后,我們需要新的教育系統,來幫助失去工作的人獲得新的技能。政府應該為這些愿意學習新技能的人,提供基本收入保障,重新成為勞動者的一員。我們需要新的系統和結構,來讓幫助社會向新世界進化。雖然會有新類型的工作,但工作崗位的消失也比以前更快。
一些問題
大公司在數據和人才上有巨大優勢,那么創業公司的機會在哪里? 投資者可以關注哪種規模的創新?
在語音識別、人臉識別上,小公司非常難與大公司競爭,除非有意料之外的技術突破。同時,也有很多小垂直領域適合創業公司,比如醫療影像。有一些疾病的病例不多,如果有一千張影像,也許就涵蓋了所有所需的數據了,一些垂直領域需要的數據量也不大。
另外,AI的機遇非常多,大公司會放棄很多的小的垂直市場,因為精力有限,大的機會還研究不過來。
AI在發明創造上,有哪些進展?
還很早期。AI可以作曲,但這很主觀。20年前的技術做出來的曲子有人喜歡,有人不喜歡。有些項目用AI制作圖片特效,用特效模仿某畫家作品,這些都是小而有趣的領域。 現在還看不到有什么技術路線能發明復雜的系統。
如果摩爾定律不再成立,對AI的擴展性有什么影響?
一些高性能計算公司的硬件路線圖顯示,摩爾定律在單芯片上不再那么有效,但神經網絡、深度學習所需的計算類型在未來幾年仍然能很好地擴展。SIMD(單指令多數據)讓并行化處理負載非常容易。神經網絡很容易并行化,加速計算的空間還很大。
AI面對的諸多問題中,許多問題的瓶頸在于數據,也有很多的瓶頸在于計算速度——能便宜地處理數據的速度趕不上獲得數據的速度。所以高性能計算的路線圖應該包括這方面。
算法是AI里的特殊作料。是否應通過知識產權保護,還是繞過這個問題去設計產品? 對機器學習的研究者,是否有和AI產品經理-工程師那樣類似的流程或良性循環,來實現突破或改善研究流程?
知識產權的問題比較難講。有些公司申請了大量專利,但是是否真能帶來實質性的保護?所以我們往往從如何從戰略上思考細節,比如讓數據保護自己。
研究機構更偏好新鮮、搶眼球的東西,來發表論文。訓練新研究者的辦法通常是讀很多論文。而大家常常忽視重復論文里的試驗的重要性。不一定要把精力大量用于發明新東西,而花時間重復別人的發布結果也是很好的培訓方法。和培訓博士生一樣:去學習和理解別人的論文,重復別人的試驗,爭取獲得類似的結果,很快你就能產生自己的想法去推動最新的科技。
對希望從事機器人相關工作的機械工程學生,有哪些和AI、機器人相關的機會比較適合?
很多機械工程背景的人,在AI領域很成功。可以上一些計算機/AI課程,和AI領域的老師聊聊。一些垂直領域存在有趣的AI機器人的機會,比如精準農業。Blue River用計算機視覺來區分不同植物,比如不同品種卷心菜,選擇留下哪些,除掉哪些,來提高產量。
中國也生產和銷售很多社交和伴侶機器人,美國還沒起怎么起步。
讓AI和人配合起來的前景如何?很多AI應用是基于AI自己,如果采用AI+人的混合方案?比如自動駕駛等?
沒有統一的規則,應該跟實際情況有關。很多語音識別是為了讓人類更高效,比如通過手機。對自動駕駛汽車,可能需要10-15秒來轉換控制權,因為難讓容易分神的人快速接手駕駛,很困難。這種情況下,由AI獨立控制更安全。 所以從使用者角度來講,人類和AI混合的自動化比較困難。
對在線教育而言,主要問題是動機,人們不愿意花那么多時間來學完整個課程。這是不是最大的挑戰? 其他還有什么挑戰?
AI對在線教育有幫助。個性化的輔導已經談論了很長時間,Coursera用AI推薦個性化的課程,自動打分,在細節上確實有幫助。但在利用AI之前,教育的數字化還有很長的路要走。很多行業都有個規律:先有數據,再有AI,比如醫療,美國電子病歷(EHR)的進展很大。隨著電子病歷的興起,影像膠片變成數碼圖片,這些數字化產生了很多數據供AI使用,并產生價值。教育需要先經歷數字化,這一階段還有很多工作要做。
百度如何用AI來管理自己的云上數據中心? 比如IT運維管理的例子?
兩年前,百度做了個項目,可以提前一天自動檢測出硬件故障,特別是硬盤故障。這就可以事先拷貝、熱插拔進行預防處理。還可以降低數據中心的用電量,負載均衡等,都是很多小細節的改善。
能否舉一些例子說明能通過仔細地建模和規劃,用AI解決的復雜問題?對這些問題,人類可能需要進行長時間的思考。
亞馬遜是個很好的例子。它知道我瀏覽過什么,讀過什么,比我太太更了解。電腦對人們看過什么,點擊過什么廣告更了解,所以在廣告方面做得非常好。 對于有些任務,計算機可以處理的信息量遠遠超過人類,并根據規律建模,進行預測,這方面AI比人做得更好。
將AI融入人類工作的很大一部分,是將一塊塊的AI部分串成一個大系統。比如為了造自動駕駛汽車,要用相機拍攝的圖像,雷達等,組成車前方的一幅圖,再由監督學習估算和其他車的距離,以及和行人的距離,這只是兩個重要的AI部件,還需要其他的部件來估計5秒后車的位置,行人的方向。還有一個部件來分析,根據行人車輛等不同對象的運動情況,我應該怎么走? 然后還需要算方向盤的旋轉程度,以此類推。
所以復雜的AI系統有很多小AI部件,工程人員要知道如何將這種超級學習能力融合到更大的系統里,來創造價值。
產品經理和社會學家、律師等如何協調?比如自動駕駛汽車在撞人前,開發者和AI應從駕駛者,還是行人的角度考慮問題?這只是個法律問題,但也有很多類似情況。產品管理者和不同的功能部門的合作時,應該扮演什么角色?
這個問題的一個相似版本是“有軌電車”問題,會產生倫理矛盾。一個電車走到岔道口,繼續往前會撞死5個人,你可以用扳手將電車扳到另一條軌道,撞死該軌道上的一個人,而你成為兇手,你扳嗎?
除了在哲學課里,很少有誰在現實生活里遇到過這個問題,所以,它并不重要。自動駕駛的開發者沒去討論它。實際上,如果誰真正遇到了,可能之前已經犯了其他錯誤了。自動駕駛處理的問題更實際,和你自己開車一樣。比如,對面有個白色的大車,是否能及時剎車?


- 上一篇:淺析視頻通信深入政企市場,為何如此受關注?
- 下一篇:那些關于視頻云會議的愚人節笑話
相關閱讀:
-
分享本文到:
-
關注隨銳:

微信掃描,獲取最新資訊 -
聯系我們:
如果您有任何問題或建議,
請與我們聯系:
suiruikeji@suirui.com
 掃碼關注微信眾公號
掃碼關注微信眾公號 抖音掃一掃 關注隨銳
抖音掃一掃 關注隨銳 China
China
